本文首发于 Computer 杂志,由InfoQ和IEEE呈现给您。 CAP理论断言任何基于网络的数据共享系统,最多只能满足数据一致性、可用性、分区容忍性三要素中的两个要素。但是通过显式处理分区情形,系统设计师可以做到优化数据一致性和可用性,进而取得三者之间的平
本文首发于  Computer 杂志,由InfoQ和IEEE呈现给您。
CAP理论断言任何基于网络的数据共享系统,最多只能满足数据一致性、可用性、分区容忍性三要素中的两个要素。但是通过显式处理分区情形,系统设计师可以做到优化数据一致性和可用性,进而取得三者之间的平衡。
自打引入CAP理论的十几年里,设计师和研究者已经以它为理论基础探索了各式各样新颖的分布式系统,甚至到了滥用的程度。NoSQL运动也将CAP理论当作对抗传统关系型数据库的依据。
CAP理论主张任何基于网络的数据共享系统,都最多只能拥有以下三条中的两条:
CAP理论的表述很好地服务了它的目的,即开阔设计师的思路,在多样化的取舍方案下设计出多样化的系统。在过去的十几年里确实涌现了不计其数的新系统,也随之在数据一致性和可用性的相对关系上产生了相当多的争论。“三选二”的公式一直存在着误导性,它会过分简单化各性质之间的相互关系。现在我们有必要辨析其中的细节。实际上只有“在分区存在的前提下呈现完美的数据一致性和可用性”这种很少见的情况是CAP理论不允许出现的。
虽然设计师仍然需要在分区的前提下对数据一致性和可用性做取舍,但具体如何处理分区和恢复一致性,这里面有不计其数的变通方案和灵活度。当代CAP实践应将目标定为针对具体的应用,在合理范围内最大化数据一致性和可用性的“合力”。这样的思路延伸为如何规划分区期间的操作和分区之后的恢复,从而启发设计师加深对CAP的认识,突破过去由于CAP理论的表述而产生的思维局限。
Why "2 of 3" is missleading 为什么“三选二”公式有误导性理解CAP理论的最简单方式是想象两个节点分处分区两侧。允许至少一个节点更新状态会导致数据不一致,即丧失了C性质。如果为了保证数据一致性,将分区一侧的节点设置为不可用,那么又丧失了A性质。除非两个节点可以互相通信,才能既保证C又保证A,这又会导致丧失P性质。一般来说跨区域的系统,设计师无法舍弃P性质,那么就只能在数据一致性和可用性上做一个艰难选择。不确切地说,NoSQL运动的主题其实是创造各种可用性优先、数据一致性其次的方案;而传统数据库坚守ACID特性(原子性、一致性、隔离性、持久性),做的是相反的事情。下文“ACID、BASE、CAP”小节详细说明了它们的差异。
事实上,CAP理论本身就是在类似的讨论中诞生的。早在1990年代中期,我和同事构建了一系列的基于集群的跨区域系统(实质上是早期的云计算),包括搜索引擎、缓存代理以及内容分发系统1。从收入目标以及合约规定来讲,系统可用性是首要目标,因而我们常规会使用缓存或者事后校核更新日志来优化系统的可用性。尽管这些策略提升了系统的可用性,但这是以牺牲系统数据一致性为代价的。
关于“数据一致性 VS 可用性”的第一回合争论,表现为ACID与BASE之争2。当时BASE还不怎么被人们接受,主要是大家看重ACID的优点而不愿意放弃。提出CAP理论,目的是证明有必要开拓更广阔的设计空间,因此才有了“三选二”公式。CAP理论最早在1998年秋季提出,1999年正式发表3,并在2000年登上Symposium on Principles of Distributed Computing大会的主题演讲4,最终确立了该理论的正确性。
“三选二”的观点在几个方面起了误导作用,详见下文“CAP之惑”小节的解释。首先,由于分区很少发生,那么在系统不存在分区的情况下没什么理由牺牲C或A。其次,虚拟主机,C与A之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉到特定的数据或用户而有所不同。最后,这三种性质都可以在程度上衡量,并不是非黑即白的有或无。可用性显然是在0%到100%之间连续变化的,一致性分很多级别,连分区也可以细分为不同含义,如系统内的不同部分对于是否存在分区可以有不一样的认知。
要探索这些细微的差别,就要突破传统的分区处理方式,而这是一项根本性的挑战。因为分区很少出现,CAP在大多数时候允许完美的C和A。但当分区存在或可感知其影响的情况下,就要预备一种策略去探知分区并显式处理其影响。这样的策略应分为三个步骤:探知分区发生,进入显式的分区模式以限制某些操作,启动恢复过程以恢复数据一致性并补偿分区期间发生的错误。
ACID、BASE、CAPACID和BASE代表了两种截然相反的设计哲学,分处一致性-可用性分布图谱的两极。ACID注重一致性,香港服务器,是数据库的传统设计思路。我和同事在1990年代晚期提出BASE,目的是抓住当时正逐渐成型的一些针对高可用性的设计思路,并且把不同性质之间的取舍和消长关系摆上台面。现代大规模跨区域分布的系统,包括云在内,同时运用了这两种思路。
这两个术语都好记有余而精确不足,出现较晚的BASE硬凑的感觉更明显,它是“Basically Available, Soft state, Eventually consistent(基本可用、软状态、最终一致性)”的首字母缩写。其中的软状态和最终一致性这两种技巧擅于对付存在分区的场合,并因此提高了可用性。
CAP与ACID的关系更复杂一些,也因此引起更多误解。其中一个原因是ACID的C和A字母所代表的概念不同于CAP的C和A。还有一个原因是选择可用性只部分地影响ACID约束。ACID四项特性分别为:
原子性(A)。所有的系统都受惠于原子性操作。当我们考虑可用性的时候,没有理由去改变分区两侧操作的原子性。而且满足ACID定义的、高抽象层次的原子操作,实际上会简化分区恢复。
一致性(C)。ACID的C指的是事务不能破坏任何数据库规则,如键的唯一性。与之相比,CAP的C仅指单一副本这个意义上的一致性,因此只是ACID一致性约束的一个严格的子集。ACID一致性不可能在分区过程中保持,因此分区恢复时需要重建ACID一致性。推而广之,分区期间也许不可能维持某些不变性约束,所以有必要仔细考虑哪些操作应该禁止,分区后又如何恢复这些不变性约束。
隔离性(I)。隔离是CAP理论的核心:如果系统要求ACID隔离性,那么它在分区期间最多可以在分区一侧维持操作。事务的可串行性(serializability)要求全局的通信,因此在分区的情况下不能成立。只要在分区恢复时进行补偿,在分区前后保持一个较弱的正确性定义是可行的。
持久性(D)。牺牲持久性没有意义,理由和原子性一样,虽然开发者有理由(持久性成本太高)选择BASE风格的软状态来避免实现持久性。这里有一个细节,分区恢复可能因为回退持久性操作,而无意中破坏某项不变性约束。但只要恢复时给定分区两侧的持久性操作历史记录,破坏不变性约束的操作还是可以被检测出来并修正的。通常来讲,让分区两侧的事务都满足ACID特性会使得后续的分区恢复变得更容易,并且为分区恢复时事务的补偿工作奠定了基本的条件。
CAP和延迟的联系CAP理论的经典解释,是忽略网络延迟的,但在实际中延迟和分区紧密相关。CAP从理论变为现实的场景发生在操作的间歇,系统需要在这段时间内做出关于分区的一个重要决定:
最后一步的目的是恢复一致性,以及补偿在系统分区期间程序产生的错误。



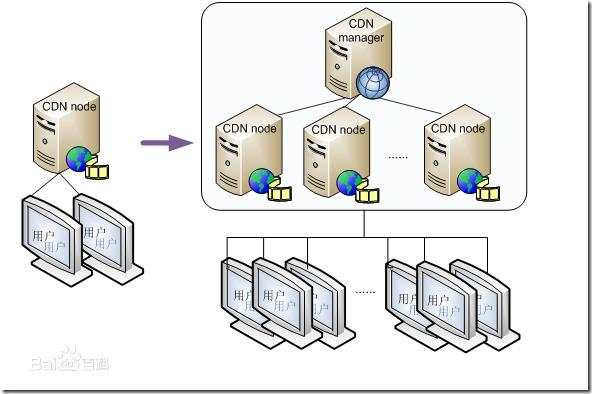






 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有