作者:东东84321 | 来源:互联网 | 2023-10-11 20:53
搭建springBoot项目
依赖:
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">4.0.0 org.springframework.boot spring-boot-starter-parent 2.3.4.RELEASE com.lagou lucene 0.0.1-SNAPSHOT lucene Demo project for Spring Boot 11 org.springframework.boot spring-boot-starter-web org.springframework.boot spring-boot-devtools runtime true org.projectlombok lombok true org.springframework.boot spring-boot-starter-test test com.baomidou mybatis-plus-boot-starter 3.3.2 javax.persistence javax.persistence-api 2.2 mysql mysql-connector-java runtime org.apache.lucene lucene-core 4.10.3 org.apache.lucene lucene-analyzers-common 4.10.3 com.janeluo ikanalyzer 2012_u6 org.apache.maven.plugins maven-compiler-plugin 11 11 utf-8 org.springframework.boot spring-boot-maven-plugin repackage 创建引导类
package com.lagou.lucene;配置properties文件
server:创建实体类、mapper、service
package com.lagou.lucene.pojo;
mapper
package com.lagou.lucene.mapper; {
package com.lagou.lucene.service; selectAll();
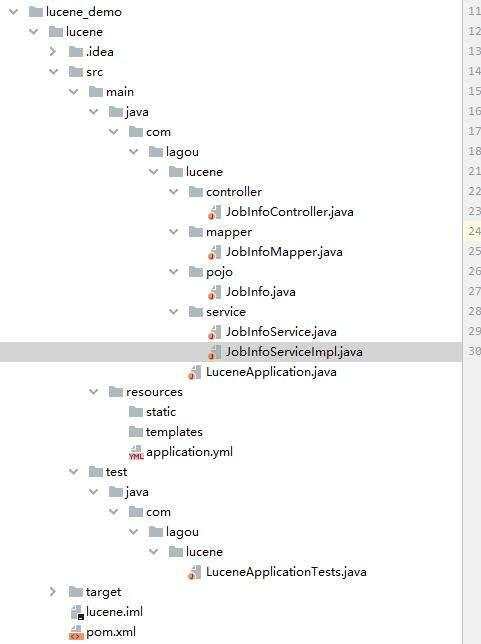
package com.lagou.lucene.service; selectAll() { wrapper = new QueryWrapper<>(); jobInfoList = jobInfoMapper.selectList(wrapper); 整体结构:
在test下创建一个包测试 package com.lagou.lucene; jobInfoList = jobInfoService.selectAll();
???????








 京公网安备 11010802041100号
京公网安备 11010802041100号