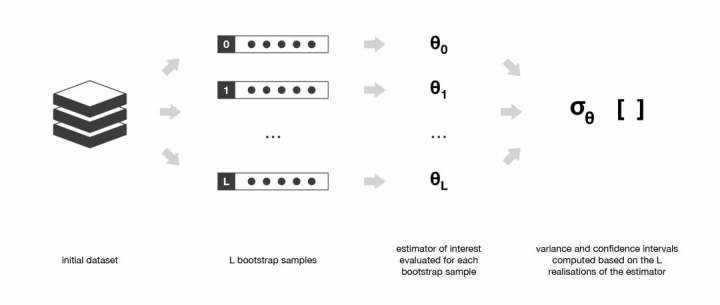
首先初始数据集的大小 N 应该足够大,以捕获底层分布的大部分复杂性。这样,从数据集中抽样就是从真实分布中抽样的良好近似(代表性)。
其次,与自助样本的大小 B 相比,数据集的规模 N 应该足够大,这样样本之间就不会有太大的相关性(独立性)。注意,接下来我可能还会提到自助样本的这些特性(代表性和独立性),但读者应该始终牢记:「这只是一种近似」。
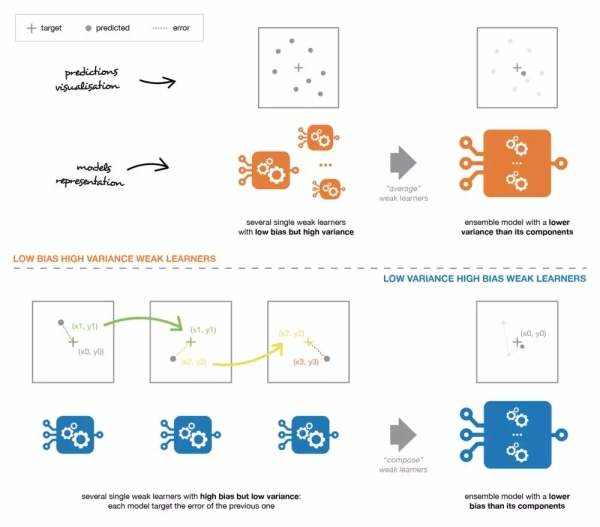
因此,假设我们面对的是一个二分类问题:数据集中有 N 个观测数据,我们想在给定一组弱模型的情况下使用 adaboost 算法。在算法的起始阶段(序列中的第一个模型),所有的观测数据都拥有相同的权重「1/N」。然后,我们将下面的步骤重复 L 次(作用于序列中的 L 个学习器):




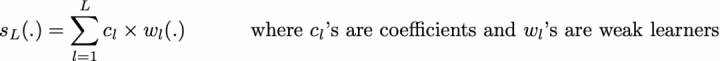
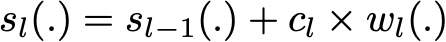
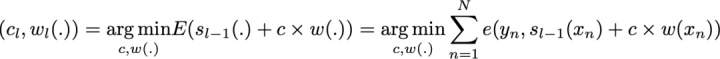



















 京公网安备 11010802041100号
京公网安备 11010802041100号