什么是标签平滑?在PyTorch中如何去使用它?
在训练深度学习模型的过程中,过拟合和概率校准(probability calibration)是两个常见的问题。一方面,正则化技术可以解决过拟合问题,其中较为常见的方法有将权重调小,迭代提前停止以及丢弃一些权重等。另一方面,Platt标度法和isotonic regression法能够对模型进行校准。但是有没有一种方法可以同时解决过拟合和模型过度自信呢?
标签平滑也许可以。它是一种去改变目标变量的正则化技术,能使模型的预测结果不再仅为一个确定值。标签平滑之所以被看作是一种正则化技术,是因为它可以防止输入到softmax函数的最大logits值变得特别大,从而使得分类模型变得更加准确。
在这篇文章中,我们定义了标签平滑化,在测试过程中我们将它应用到交叉熵损失函数中。
标签平滑?
假设这里有一个多分类问题,在这个问题中,目标变量通常是一个one-hot向量,即当处于正确分类时结果为1,否则结果是0。
标签平滑改变了目标向量的最小值,使它为ε。因此,当模型进行分类时,其结果不再仅是1或0,而是我们所要求的1-ε和ε,从而带标签平滑的交叉熵损失函数为如下公式。

在这个公式中,ce(x)表示x的标准交叉熵损失函数,例如:-log(p(x)),ε是一个非常小的正数,i表示对应的正确分类,N为所有分类的数量。
直观上看,标记平滑限制了正确类的logit值,并使得它更接近于其他类的logit值。从而在一定程度上,它被当作为一种正则化技术和一种对抗模型过度自信的方法。
PyTorch中的使用
在PyTorch中,带标签平滑的交叉熵损失函数实现起来非常简单。首先,让我们使用一个辅助函数来计算两个值之间的线性组合。
deflinear_combination(x, y, epsilon):return epsilon*x + (1-epsilon)*y
下一步,我们使用PyTorch中一个全新的损失函数:nn.Module.
import torch.nn.functional as F
defreduce_loss(loss, reduction='mean'):return loss.mean() if reduction=='mean'else loss.sum() if reduction=='sum'else loss
classLabelSmoothingCrossEntropy(nn.Module):def__init__(self, epsilon:float=0.1, reduction='mean'):
super().__init__()
self.epsilon = epsilon
self.reduction = reduction
defforward(self, preds, target):
n = preds.size()[-1]
log_preds = F.log_softmax(preds, dim=-1)
loss = reduce_loss(-log_preds.sum(dim=-1), self.reduction)
nll = F.nll_loss(log_preds, target, reduction=self.reduction)
return linear_combination(loss/n, nll, self.epsilon)
我们现在可以在代码中删除这个类。对于这个例子,我们使用标准的fast.ai pets example.
from fastai.vision import *
from fastai.metrics import error_rate
# prepare the data
path = untar_data(URLs.PETS)
path_img = path/'images'
fnames = get_image_files(path_img)
bs = 64
np.random.seed(2)
pat = r'/([^/]+)_\d+.jpg$'
data = ImageDataBunch.from_name_re(path_img, fnames, pat, ds_tfms=get_transforms(), size=224, bs=bs) \
.normalize(imagenet_stats)
# train the model
learn = cnn_learner(data, models.resnet34, metrics=error_rate)
learn.loss_func = LabelSmoothingCrossEntropy()
learn.fit_one_cycle(4)
最后将数据转换成模型可以使用的格式,选择ResNet架构并以带标签平滑的交叉熵损失函数作为优化目标。经过四轮循环后,其结果如下

我们所得结果的错误率仅为7.5%,这对于10行左右的代码来说是完全可以接受的,并且在模型中大多数参数还都选择的是默认设置。
因此,在模型中还有许多参数可以进行调整,从而使得模型的表现性能更好,例如:可以使用不同的优化器、超参数、模型架构等。
结论
在这篇文章中,我们了解了什么是标签平滑以及什么时候去使用它,并且我们还知道了如何在PyTorch中实现它。之后,我们训练了一个先进的计算机视觉模型,仅使用十行代码就识别出了不同品种的猫和狗。
模型正则化和模型校准是两个重要的概念。若想成为一个深度学习的资深玩家,就应该好好地去理解这些能够对抗过拟合和模型过度自信的工具。
作者简介: Dimitris Poulopoulos,是BigDataStack的一名机器学习研究员,同时也是希腊Piraeus大学的博士。曾为欧盟委员会、欧盟统计局、国际货币基金组织、欧洲央行等客户设计过与AI相关的软件。
总结
到此这篇关于如何在PyTorch中使用标签平滑正则化的文章就介绍到这了,更多相关PyTorch正则化内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!









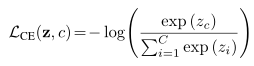

 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有