作者:廖赞胜 | 来源:互联网 | 2024-10-12 18:02
篇首语:本文由编程笔记#小编为大家整理,主要介绍了大数据采集:爬虫框架之WebMagic的基本使用相关的知识,希望对你有一定的参考价值。
本文转载:大米锅巴加点盐
 webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/COOKIE等功能。作为爬虫框架,它使用httpclient作为获取网页工具、使用Jsoup作为分析页面定位抓取内容、使用ExecutorService线程池作为定时增量抓取、Jdiy作为持久层框架。不熟悉这些名词的同学们可以先行百度一下这些都是什么,起了什么作用,以便更好的理解爬虫的原理。
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。webmagic采用完全模块化的设计,功能覆盖整个爬虫的生命周期(链接提取、页面下载、内容抽取、持久化),支持多线程抓取,分布式抓取,并支持自动重试、自定义UA/COOKIE等功能。作为爬虫框架,它使用httpclient作为获取网页工具、使用Jsoup作为分析页面定位抓取内容、使用ExecutorService线程池作为定时增量抓取、Jdiy作为持久层框架。不熟悉这些名词的同学们可以先行百度一下这些都是什么,起了什么作用,以便更好的理解爬虫的原理。
爬虫主要思想分这么几步:
1. 根据种子链接,抽取目标链接放入待爬取队列
2. 从页面中解析并抽取需要的信息,webmagic在这里会用Jsoup组件来解析html页面。
3. 处理数据。将已提取出来的数据以文件格式存放或者存入数据库以及搜索引擎索引库等。
此处以爬取天涯论坛某个栏目下的帖子主题和链接为例(示例比较简单,仅供大家入门参考):
要爬取的种子链接页面如下,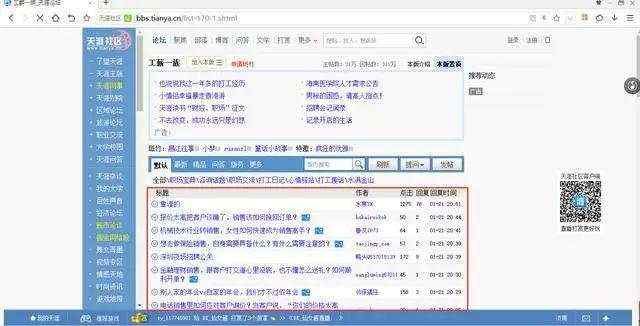
配置java工程及导入webmagic的核心jar等操作步骤此处不再详细描述,下面说一下代码示例。
首先,需要新建一个实现PageProcessor接口的类,复写process方法。部分截图如下: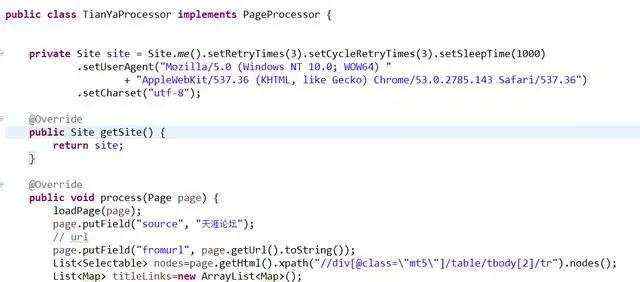
程序结构:
第一步,抽取目标链接放入待爬取队列。
说明:
程序启动入口处设置种子链接并设置相应的Pipeline(第三步会讲PipeLine怎么写),定义爬取时使用的线程数,并使用webmagic监控(这一句话:SpiderMonitor.instance().register(CastSpider))。
代码如下:
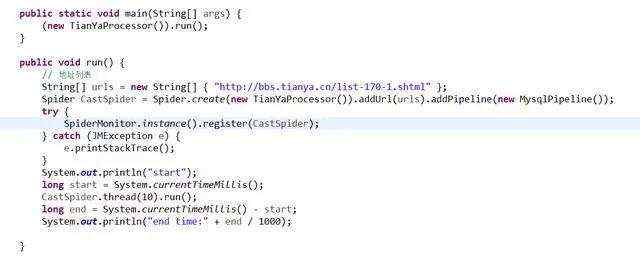
此处从页面html中提取所有翻页的链接并使用正则表达式筛选后放入待爬取队列:
第二步,从页面中解析并抽取需要的信息。此处获取帖子主题、作者、点击数、回复数、最后回复时间,process方法内示例:

第三步,处理数据。此处以存放入mysql数据库为例,定义一个MysqlPipeline,实现Pipeline接口。
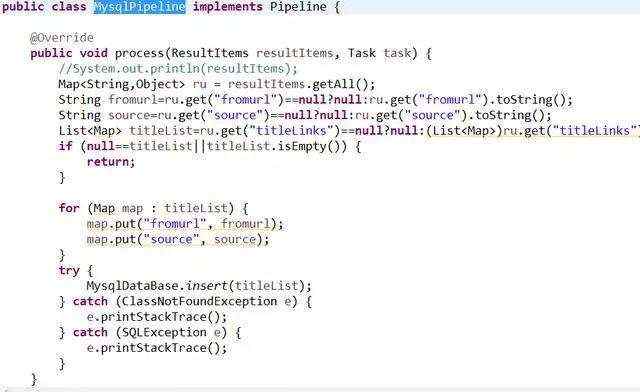
最后,大功告成,启动运行后,数据库中存储的数据如下:
怎么样,是不是很简单?大家一起试着写写,从网上爬点要的数据吧。
不能空想理论和架构,搞软件研发相关工作的同学们,该动手时就要动手!学习编程开发没有捷径,一定要动手来写!





 京公网安备 11010802041100号
京公网安备 11010802041100号