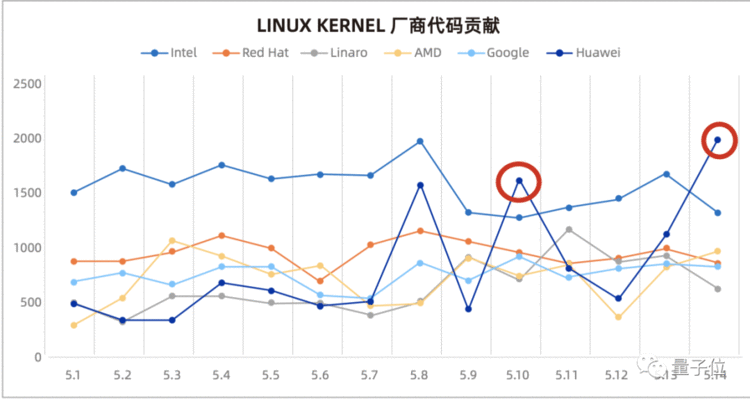
我正在使用以下基于另一个答案的SQL代码。但是,当包含大量in子句时,获取总数需要花费太长时间。如果删除总数,则查询将花费不到1秒的时间。有没有更有效的方法来获取总行数?我看到的答案基于2013 SQL查询。
DECLARE
@PageSize INT = 10,
@PageNum INT = 1;
WITH TempResult AS(
SELECT ID, Name
FROM Table
Where ID in ( 1 ,2 3, 4, 5, 6, 7, 8, 9 ,10)
), TempCount AS (
SELECT COUNT(*) AS MaxRows FROM TempResult
)
SELECT *
FROM TempResult,
TempCount <----- this is what is slow. Removing this and the query is super fast
ORDER BY TempResult.Name
OFFSET (@PageNum-1)*@PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY
Thailo.. 5
据我所知,除了使用已经提到的#temp表方法之外,还有3种方法可以实现此目的。在下面的测试案例中,我使用了具有6CPU / 16GB RAM的SQL Server 2016 Developer实例,以及一个包含约2500万行的简单表。
方法1:交叉加入
DECLARE
@PageSize INT = 10
, @PageNum INT = 1;
WITH TempResult AS (SELECT
id
, shortDesc
FROM dbo.TestName
WHERE id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
SELECT
*, MaxRows
FROM TempResult
CROSS JOIN (SELECT COUNT(1) AS MaxRows FROM TempResult) AS TheCount
ORDER BY TempResult.shortDesc OFFSET (@PageNum - 1) * @PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY;
测试结果1:
方法2:COUNT(*)OVER()
DECLARE
@PageSize INT = 10
, @PageNum INT = 1;
WITH TempResult AS (SELECT
id
, shortDesc
FROM dbo.TestName
WHERE id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
)
SELECT
*, MaxRows = COUNT(*) OVER()
FROM TempResult
ORDER BY TempResult.shortDesc OFFSET (@PageNum - 1) * @PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY;
测试结果2:
方法3:第二次CTE
测试结果3(使用的T-SQL与问题中的相同):
结论
最快的方法取决于您的数据结构(和总行数)以及服务器的大小/负载。以我为例,使用COUNT(*)OVER()被证明是最快的方法。为了找到最适合您的方案,您必须测试最适合您的方案。并且也不排除#table方法还没有;-)
据我所知,除了使用已经提到的#temp表方法之外,还有3种方法可以实现此目的。在下面的测试案例中,我使用了具有6CPU / 16GB RAM的SQL Server 2016 Developer实例,以及一个包含约2500万行的简单表。
方法1:交叉加入
DECLARE
@PageSize INT = 10
, @PageNum INT = 1;
WITH TempResult AS (SELECT
id
, shortDesc
FROM dbo.TestName
WHERE id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
SELECT
*, MaxRows
FROM TempResult
CROSS JOIN (SELECT COUNT(1) AS MaxRows FROM TempResult) AS TheCount
ORDER BY TempResult.shortDesc OFFSET (@PageNum - 1) * @PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY;
测试结果1:
方法2:COUNT(*)OVER()
DECLARE
@PageSize INT = 10
, @PageNum INT = 1;
WITH TempResult AS (SELECT
id
, shortDesc
FROM dbo.TestName
WHERE id IN (1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
)
SELECT
*, MaxRows = COUNT(*) OVER()
FROM TempResult
ORDER BY TempResult.shortDesc OFFSET (@PageNum - 1) * @PageSize ROWS
FETCH NEXT @PageSize ROWS ONLY;
测试结果2:
方法3:第二次CTE
测试结果3(使用的T-SQL与问题中的相同):
结论
最快的方法取决于您的数据结构(和总行数)以及服务器的大小/负载。以我为例,使用COUNT(*)OVER()被证明是最快的方法。为了找到最适合您的方案,您必须测试最适合您的方案。并且也不排除#table方法还没有;-)
与性能相关的问题的第一步将是分析表/索引结构,并检查查询计划。您尚未提供该信息,所以我将自行整理,然后从那里开始。
我将假设您有一个堆,其中有约1000万行(对我来说是12,872,738):
DECLARE @MaxRowCount bigint = 10000000,
@Offset bigint = 0;
DROP TABLE IF EXISTS #ExampleTable;
CREATE TABLE #ExampleTable
(
ID bigint NOT NULL,
Name varchar(50) COLLATE DATABASE_DEFAULT NOT NULL
);
WHILE @Offset <@MaxRowCount
BEGIN
INSERT INTO #ExampleTable
( ID, Name )
SELECT ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL )),
ROW_NUMBER() OVER ( ORDER BY ( SELECT NULL ))
FROM master.dbo.spt_values SV
CROSS APPLY master.dbo.spt_values SV2;
SET @Offset = @Offset + ROWCOUNT_BIG();
END;
如果我运行over over提供的查询#ExampleTable,则大约需要4秒钟,并给出以下查询计划:
无论如何,这都不是一个很好的查询计划,但这并不可怕。使用实时查询统计数据运行时,显示基数估计最多相差一个,这很好。
让我们给出IN列表中的大量项目(1-5000中有5000个项目)。编制计划花了4秒钟:
在查询处理器停止处理之前,我最多可以获取15000个项目的编号,而查询计划没有任何变化(编译过程总共需要6秒钟)。在我的计算机上运行两个查询大约需要5秒钟。
对于分析工作负载或数据仓库来说,这可能很好,但是对于像OLTP这样的查询,我们肯定超出了我们的理想时间限制。
让我们看一些替代方案。我们可能可以将其中一些组合在一起。
我们可以将IN列表缓存在临时表或表变量中。
我们可以使用窗口函数来计算计数
我们可以将CTE缓存在临时表或表变量中
如果在足够高的SQL Server版本上,请使用批处理模式
更改表上的索引以使其更快。
如果这是用于OLTP工作流程,那么无论我们有多少用户,我们都需要快速的东西。因此,我们希望最大程度地减少重新编译,并且希望在任何可能的地方进行索引查找。如果这是分析或仓储,则重新编译和扫描可能很好。
如果我们需要OLTP,则缓存选项可能不在表格中。临时表将始终强制重新编译,而依赖良好估计的查询中的表变量要求您强制重新编译。替代方法是让应用程序的其他部分维护具有分页计数或过滤器(或两者都有)的持久表,然后对此进行联接。
如果同一用户将查看许多页面,那么即使在OLTP中缓存掉一部分页面仍然值得,但是请确保您衡量了许多并发用户的影响。
不管工作流程如何,更新索引都可以(除非您的工作流程确实会使索引维护陷入困境)。
无论工作流程如何,批处理模式都是您的朋友。
无论工作流程如何,窗口函数(尤其是具有索引和/或批处理模式的窗口函数)可能都会更好。
通过传统的基数估计器和行模式执行,我们几乎总是得到差的基数估计(以及由此产生的计划)。强制默认基数估计值有助于第一个,而批处理模式则有助于第二个。
如果您无法更新数据库以使用新的基数估计器批发,则需要为特定查询启用它。为此,可以使用以下查询提示:OPTION( USE HINT( 'FORCE_DEFAULT_CARDINALITY_ESTIMATION' ) )获取第一个。第二,向CCI添加一个LEFT OUTER JOIN dbo.EmptyCciForRowstoreBatchmode ON 1 = 0联接(不需要返回数据):-这使SQL Server可以选择批处理模式优化。这些建议假定使用了足够新的SQL Server版本。
CCI无关紧要;为了保持一致性,我们希望保留一个空白,如下所示:
CREATE TABLE dbo.EmptyCciForRowstoreBatchmode ( __zzDoNotUse int NULL, INDEX CCI CLUSTERED COLUMNSTORE );
我不修改表就可以得到的最好计划是同时使用它们。使用与以前相同的数据,运行时间不到1秒。
WITH TempResult AS
(
SELECT ID,
Name,
COUNT( * ) OVER ( ) MaxRows
FROM #ExampleTable
WHERE ID IN ( <> )
)
SELECT TempResult.ID,
TempResult.Name,
TempResult.MaxRows
FROM TempResult
LEFT OUTER JOIN dbo.EmptyCciForRowstoreBatchmode ON 1 = 0
ORDER BY TempResult.Name OFFSET ( @PageNum - 1 ) * @PageSize ROWS FETCH NEXT @PageSize ROWS ONLY
OPTION( USE HINT( 'FORCE_DEFAULT_CARDINALITY_ESTIMATION' ) );







 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有