文章部分内容参考自captainbed.net
[TOC]
之前的人工智能(聚类、专家系统、归纳逻辑)都是假智能,与其说是人工智能,倒不如说是统计智能。都只是一个较为复杂的大型程序而已,我们仍然清楚其内部如何运行。
而神经网络则不同,其内部是一个黑盒子,我们丝毫不知道他是如何实现的。
神经网络是受人类大脑神经细胞的启发而构造出来的,每一个节点接受若干权值的输入,如果满足一定条件,就输出,否则不输出。
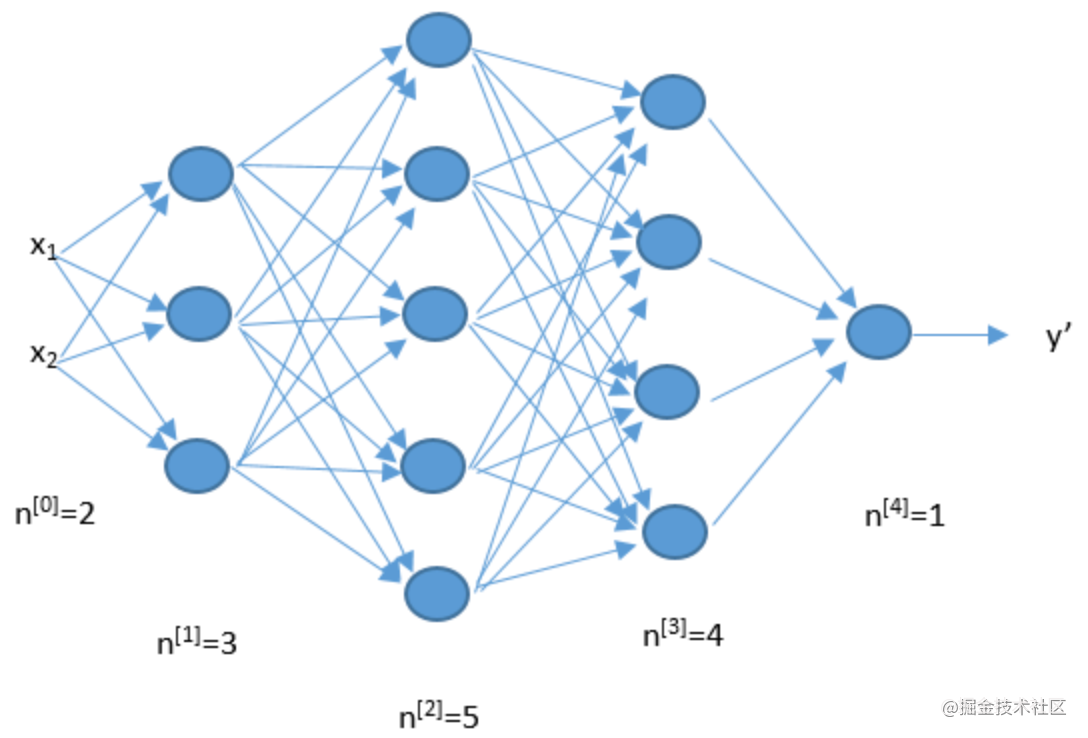
其中x代表输入的训练集,y代表输出的结果。
网络越复杂神经网络就越强大 所以我们需要深度神经网络。这里的深度是指层数多,层数越多那么构造的神经网络就越复杂。
训练深度神经网络的过程就叫做深度学习 网络构建好了后,我们只需要负责不停地将训练数据输入到神经网络中,它内部就会自己不停地发生变化不停地学习,而我们不知道它是如何学习的。
每一个输入到神经网络的数据都被叫做一个特征,例如向图像识别神经网络输入一个有64*64*3(64*64是分辨率,3是3种原色)个像素的图片。这个12288维的图片也被叫做_有12288个特征的特征向量_。
人工智能常用的一些基础概念如下:
样本就是用来训练模型的一些实例,分为有标签样本和无标签样本,
标签是我们要预测的事物,举例来说,判断一个动物图片是不是猫。“猫”就是标签;或者预测房子的价格,“价格”就是标签。标签是可以确定的。
特征是输入的变量,==可以理解影响结果为“因素”==,复杂的机器学习项目中可能会有上百万个特征。在垃圾邮件检测中,特征可能包括:邮件中的字词、发件人的地址、发送的时间、发送的频率...(不难想到这些因素都可能影响是否判定当前邮件为垃圾邮件的结果)。
出现频率高、与标签关系高的特征是价值高的特征,我们要避免很少出现的特征,例如邮件的ID。
模型定义了特征和标签之间的关系。例如,垃圾邮件检测模型可能会将邮件中的出现某些广告词汇这一特征与“垃圾邮件”联系起来。模型生命周期的两个阶段:
也就是先学,学好了就用。










 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有 
