作者:有你真好-LOVE | 来源:互联网 | 2023-05-25 18:33
数字经济的时代,数据成为企业的核心资产。企业期望通过对数据的洞察来驱动业务决策,然而获取数据洞察还需要经过数据采集、存储、处理、分析等众多环节。
什么是数据目录?
如果将数据处理的过程简单抽象一下,就是先使用一个 ETL(提取、转换和加载)工具来进行数据分析前的数据准备工作,然后将处理好的元数据信息存储到数据目录中,最后终端用户通过数据目录来查找和消费数据。
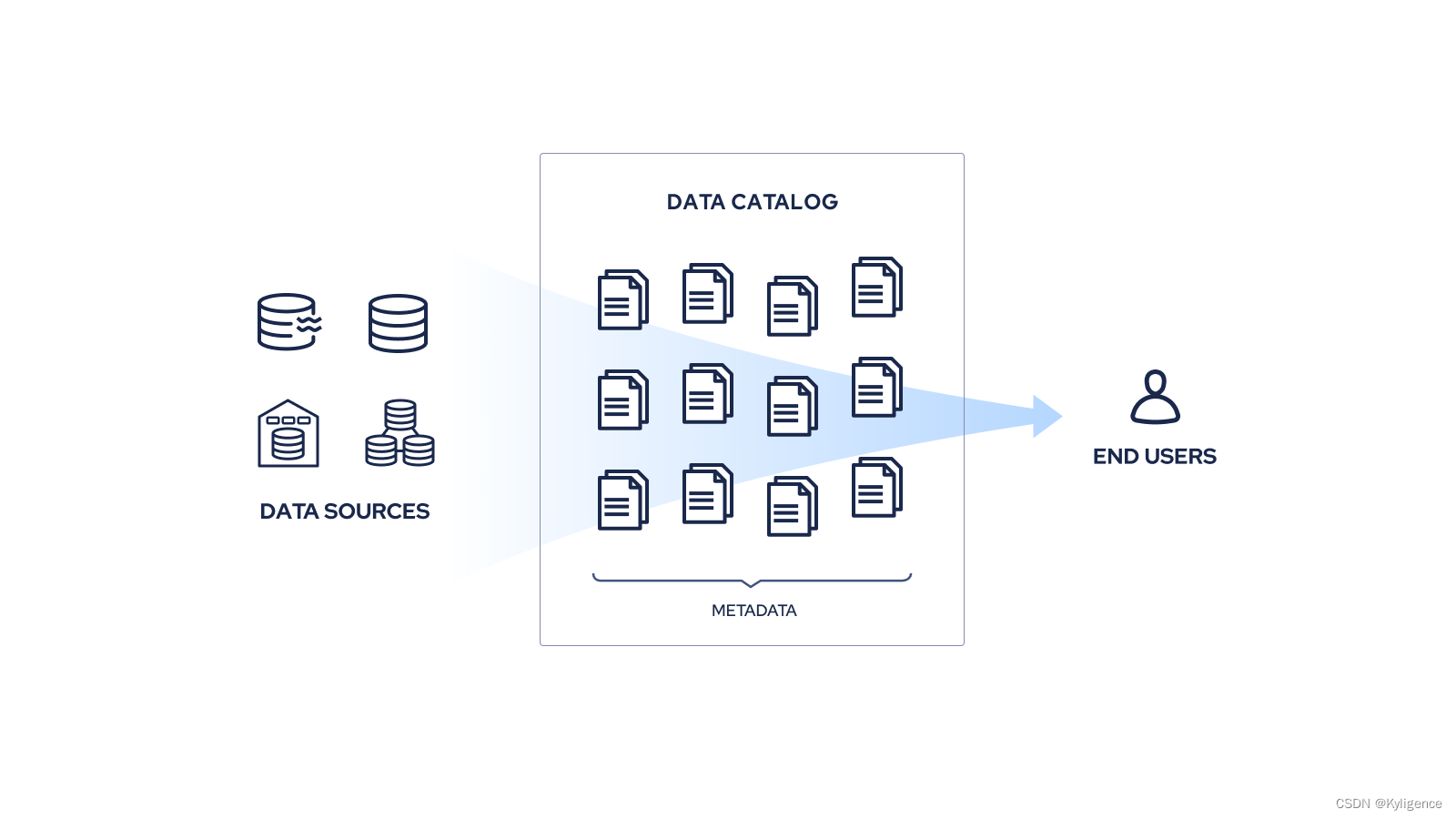
其中,数据目录串联起了整个数据链路,它是企业所有数据资产的详细清单,帮助终端用户针对任何分析或业务目的快速找到所需数据。数据目录使用元数据来管理数据资产,通过不断收集和整理元数据为数据发现和治理提供支持。
云原生的统一数据目录
对于企业来说,数据从业务系统源头到数据最终的消费端,需要经过多次流转,想从数据海洋中找到正确的数据更加困难。数据目录的出现解决了这一难题。但是在企业实际的落地过程,由于牵扯到多种数据产品的集成,往往存在需要同时维护多个数据目录的情况出现,无形之中造成了资源的冗余和数据流转不畅,数据团队不得不花费大量精力在数据查找和更新中。
如果有一个统一的数据目录,能让下游的各种大数据分析应用直接进行消费,而无需额外管理新的数据目录,将能极大地提高数据分析的速度和质量。对于云上用户来说,如果能直接利用云平台提供的原生数据目录服务作为统一的数据目录将极大地提升云上分析效率和使用体验。
Kyligence Cloud 数据目录
出于上述原因,Kyligence Cloud 在最新的版本中支持了与 Amazon Glue 云原生数据目录的集成,实现了数据目录的统一管理。
Kyligence Cloud 元数据管理
Kyligence Cloud 是由 Kyligence 推出的云原生智能多维数据库平台,提供海量数据之上的高性能高并发查询能力,为企业简化数据湖上的多维数据分析(OLAP)。
此前,Kyligence Cloud 通过内置数据目录来实现产品内部的元数据信息管理。用户在消费数据前,需要在 Kyligence Cloud 中创建表,提供表结构、数据类型和数据所在位置等信息。如果客户的数据目录是在 Amazon Glue 托管的,则需要在 Kyligence Cloud 额外维护一份相同的元数据信息,当元数据发生变更时,需要手动去同步这些变化。并且若数据分散在不同的云账户下时,需要先把数据汇集到同一个账号下某个区域的存储桶中供 Kyligence Cloud 读取,然后再进行 OLAP 分析,这在一定程度上增加了客户的数据流转和数据存储成本。
Kyligence Cloud 集成 Amazon Glue 数据目录
在最新的 Kyligence Cloud 版本中,通过与 Amazon Glue 标准的 Apache Hive 接口集成,用户可以直接使用 Amazon Glue 提供的元数据存储和管理服务,通过支持跨区域和跨账号的 S3 存储桶的数据管理,实现对任何位置、任何账号下数据的统一数据目录管理。
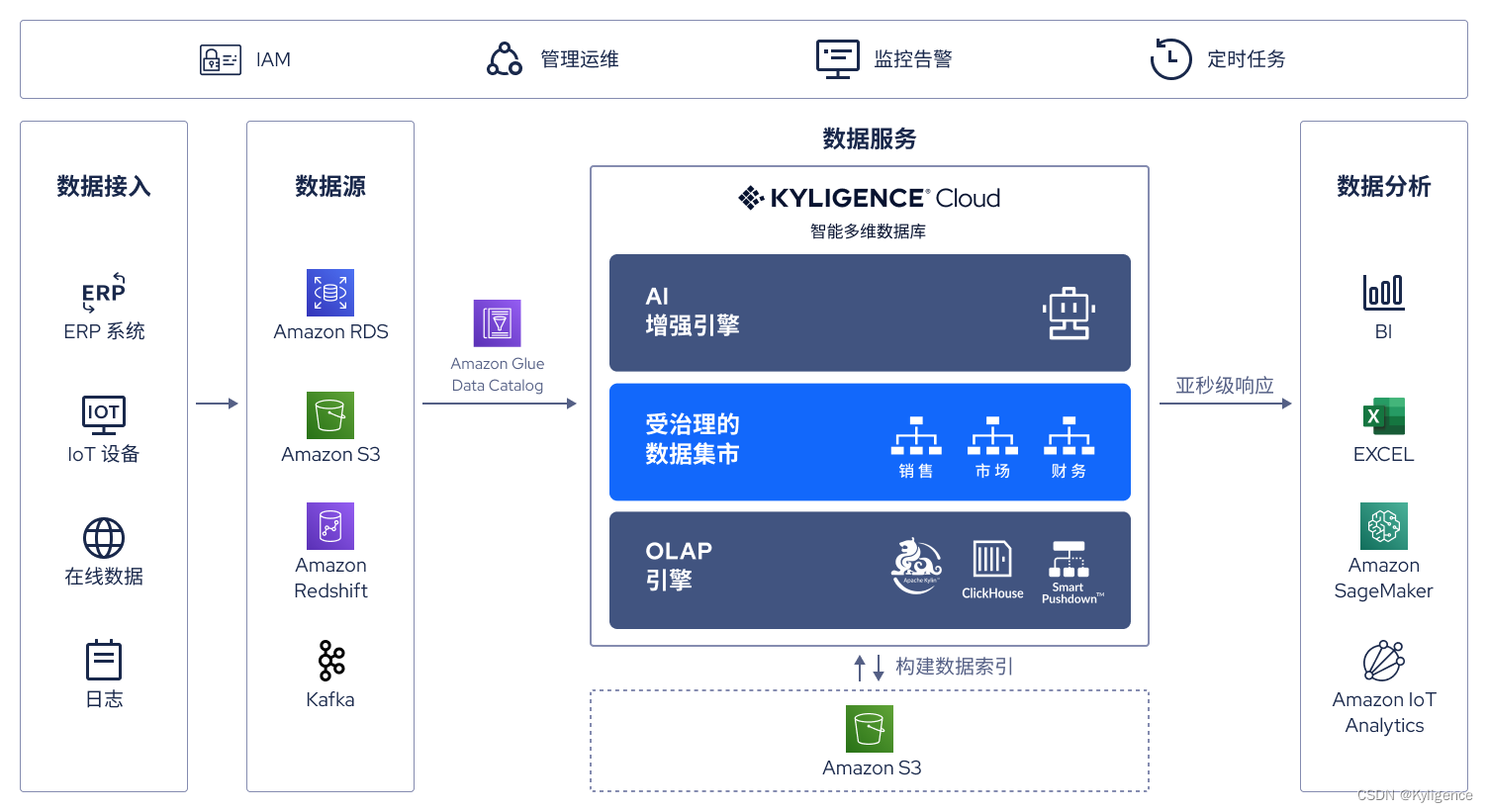
Amazon Glue 数据目录作为数据源接入 Kyligence Cloud
根据亚马逊云科技官方文档介绍,Amazon Glue 数据目录完全兼容 Apache Hive Metastore,并且 Amazon Glue 提供了与 Amazon EMR 的开箱即用集成方案,使用户能够将 Amazon Glue 数据目录用作外部 Hive Metastore。这个方案除了 Amazon EMR,也可以移植到其他 Hive Metastore 的兼容平台上。
Kyligence Cloud 通过此特性,可按需动态读取 Amazon Glue 数据目录中的数据库/表等信息,服务于后续数据的建模和查询。Kyligence Cloud 只需要拥有客户 Amazon Glue 相关库表的读取权限即可,不需要对客户 Glue 数据目录中的任何信息进行修改,充分确保了用户的信息安全。
统一数据目录之后的 Kyligence Cloud 可以让用户便捷地发现组织中的数据,并借助 AI 增强引擎实现数据查询的优化,最终让终端业务人员在 BI 分析工具中获得快速查询体验。
总结
Amazon Glue 为用户提供了一种简单易用的数据目录管理方式,帮助用户轻松找到并访问数据。
Kyligence Cloud 则通过集成 Amazon Glue 数据目录,帮助用户实现统一的元数据管理,不仅降低了数据流转带来的成本,还提升了数据分析的效率。











 京公网安备 11010802041100号
京公网安备 11010802041100号